Gordonjcp was wanting to have a set of offline tiles for his 'phone along a route he is taking tomorrow. The ability to create a limited set of tiles would get round some of the problems associated with tile scraping, limited storage space, and time taken to create the tiles.
However, there aren't any obvious apps which do this. It occurred to me that it might be possible to limit this on the SQL side with little or no change to the standard generate_tiles.py script which is distributed with the OpenStreetMap mapnik renderer.
The idea was so simple it was worth trying out. I already had a PostGIS database containing (fairly) recent data for Great Britain, so all I had to do was import a route into the same database and create views which limited the OSM data to areas adjacent to the route. This is a very simple-minded hack, but it seems to work reasonably well and it may be possible to improve it by adding a little code to the existing python script.
For a route I chose a GPX track I uploaded recently. There are plenty of other ways of generating a similar track: notably by using an on-line routing engine and saving the route as a GPX (for instance Open MapQuest, OpenRouteService or Cloudmade). To get the GPX track into PostGIS I used Quantum GIS to save the track as a shapefile and the SPIT extension to upload this to PostGIS. In PostGIS I added two extra geometry columns to this one row table, and updated these with the track itself and the track surrounded by a 1 km buffer:
For each of the 4 main planet_osm_* tables I created a view as follows:
UPDATE route_track
SET geom_goog = ST_SETSRID(ST_TRANSFORM(geom_wgs,900913),900913)
, geom_goog_buffer = ST_SETSRID(ST_BUFFER(
ST_TRANSFORM(geom_wgs,900913),1000),900913);
CREATE OR REPLACE VIEW planet_osm_lineXI ran SELECT populate_geometry_columns() to ensure the geometry columns were accessible to PostGIS operations. It would be possible to rename the planet_osm_* tables and create the views instead of them. This would avoid the need to create an extra copy of the mapnik XML file, which is what I did next.
AS
SELECT a.*
FROM planet_osm_line a
, route_track b
WHERE ST_INTERSECTS(a.way,b.geom_goog_buff)
I made a copy of the mapnik.xml file and replaced all examples of planet_osm_* with the same string with an "X" appended.
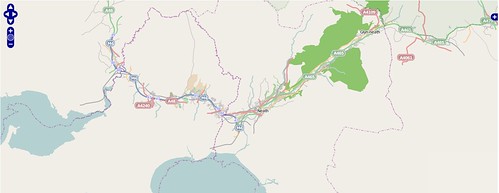
All I had to do then was add a suitable bounding box to the python script and set local variables for the map tile directory & the mapnik map file. Really the bbox should be determined from the database, but the objective was to do something quick and dirty. For my example I used a bounding box which was 2 degrees wide and 1 degree high.
Tile generation runs pretty smoothly: as one might expect lots of empty tiles are created, but the query overhead is quite reasonable. As the empty tiles are only 103 bytes each they don't take up too much space either.
There are lots of fairly simple optimisations which could be added:
- Find the bbox of the route & only generate tiles within that bbox.
- Identify empty tiles en masse and avoid running the mapnik queries against the database for these tiles.
- Replace empty tiles with links.