Andy Allan (gravitystorm) asked a very pertinent question after my talk at SotMEU: Why had I not used building outlines to automatically identify different classes of residential landuse?
Briefly, my answer was: "I had tried, but the results weren't satisfactory". This is a much longer answer than I could give at Vienna, and fills in some detail about the technical approach I used. I hope that readers may have some good suggestions to improve this approach.
It is clear that Urban Atlas data is a good model for studying landuse mapping through replication/simulation in OSM. After working with this data for six months I realise that one of the main reasons for this is that UA's main classification is simpler than the current OSM consensus for landuse mapping. Thus most UA landuse classes have a 1:M mapping to OSM tags. Other landuse and landcover schemes, such as CORINE, EUNIS, have many more classes and in thus in many cases the classes have N:1 or N:M mappings to OSM tags. Most of these relate to agriculture, woodland or natural vegetation: for the most part where OSM tag usage is only fitfully consistent, or the same tag has multiple meanings.
There are, however, 5 UA classes (Continuous and Discontinuous Urban Cover — 11100, 11210,11220, 11230 and 11240) which map on to a single tag in OSM : landuse=residential. The main criterion for separating this classes in UA is the degree of surface sealing, with continuous urban cover meaning that over 80% of the land surface is effectively sealed (buildings, asphalt, concrete etc.). As a significant proportion of surface sealing will be buildings it seems plausible to use the proportion of residential landuse covered by buildings as a proxy for surface sealing.

Buildings generated from OS OpenData using mapseg (orange) compared with those mapped in OSM using Bing imagery (light green) for OS grid square SK5038.
Buildings were then clipped to match the residential landuse parcels, and then assigned to individual parcels. Landuse parcels which had originally been created as multipolygons on a 1 km grid were decomposed to individual polygons (using ST_DUMP) before this step. Polygons meeting on grid boundaries were not re-assembled. At this point it is simple to sum the building area for each polygon and determine the ratio of the total polygon area covered by buildings. The results are graphed below with the data divided into 20 buckets.
 For comparison here is the relative distribution of the EEA UA data for the Nottingham area:
For comparison here is the relative distribution of the EEA UA data for the Nottingham area:
| UA Code | Area (ha) | % Total Residential |
| 11100 | 137 | 1.0% |
| 11210 | 7132 | 52.0% |
| 11220 | 5298 | 38.7% |
| 11230 | 846 | 6.2% |
| 11240 | 18 | 0.1% |
| 11300 | 272 | 2.0% |
The vast majority of residential landuse falls in two classes with surface sealing in the range 30 to 80%, with more than half of the landuse with greater than 50% surface sealing. A cursory comparison between the two sets of figures suggests that, at best building cover may only account for half factors used to assign surface sealing in Urban Atlas. Fortunately because I created a datasets of differences and similarities of data from UA and OSM it's possible to compare individual landuse polygons: a bit more work as these may be slightly different shapes, and therefore the whole clipping of buildings and area calculation must be repeated.
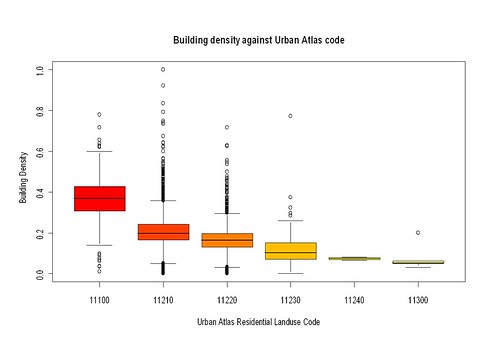
The box-plot above amply confirms the initial impression. No doubt if and when I learn more about R, a proper statistical comparison could be done. Building density from OSM does not explain enough of the UA surface sealing value to be reliable for classification. At least for now. There is enough in the plot to hint that enrichment of the data with other variables may facilitate separation, but that's a different project again.
So that's the (very) long answer to Andy's question.
What does it mean for OSM:
- Using buildings to derive sub-classes of residential landuse is not generally useful.
- The requirement for completeness in building outlines on its own means that such an approach would at the best of times only work in certain places (good external sources of building data, excellent imagery). It may also require fanatical devotion to mapping buildings.
- The basic classes of landuse we are interested can probably be derived from local knowledge, ground survey, aerial imagery etc. To make this more generally useful this requires some guidelines and consensus on tagging.
- For now we could use tags similar to the Urban Atlas codes for urban areas in Europe and North America. Significant extension of these values might be needed to adequately cope with other areas in the world. (I'll be blogging in depth on this subject soon).
- Looking at extending this type of data with other OSM derived variables may be interesting. Alexander Zipf mentioned that his group at Heidelberg had used a data mining approach to identify residential areas from OSM data.
No comments:
Post a Comment
Sorry, as Google seem unable to filter obvious spam I now have to moderate comments. Please be patient.