 |
| Wet Lamp Post, photo by Don3rdSE (all rights reserved) |
In my earlier post I mentioned that it would be nice to see if it was possible to find the location of streets simply by linking together all the lamp posts on the same street. This is a (technical) account of how I achieved this using PostGIS.
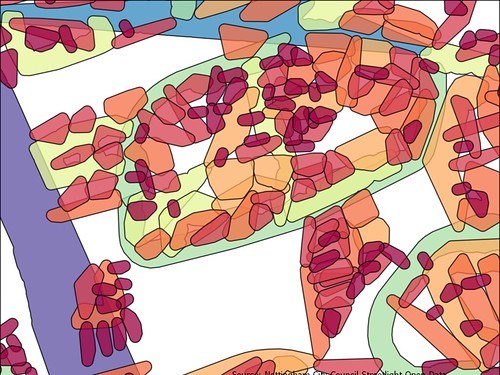 |
| Polygons representing streets captured from Street Light Open data Colours are dependent on the number of lamp posts, the area is here. |
select street_name,Great, except that it didn't work. The reason why: there are several streets in the city which share a name, and these are often on opposite sides of town (e.g., Vernon Avenue, Basford and Vernon Avenue, Wilford). In this case, and probably others, Wilford only became part of the city around 1950. So duplicate names have arisen through city expansion rather than through some absence of mind of the authorities.
ST_ConcaveHull(ST_Union(lamp_post_geom))
from lamp_posts
group by street_name
Therefore I decided to start at the base level of the data and work upwards from the lamp post positions themselves. It is easy to find each lamp post's nearest neighbour which shares the same street name. I simply placed a decent sized buffer (50-60 metres looks about sight, average distance is 29.54 m ± 16.18 )around each light's geometry and then found the lights within that geometry sharing the streetname:
where ST_Within(a.lamp_post_geom ,ST_Buffer(b.lamp_post_geom, DISTANCE)Then one selects the lamp post closest in distance, using the neat DISTINCT ON clause in PostgreSQL. This also has problems because it will find pairs of lamp posts. Therefore another predicate is needed to ensure that for each lamp post choose only one of its adjacent posts is consistently chosen. Again PostGIS offers geometry operators, and we can test if the bounding box of one lamp post is above, below, left (<<) or right (>>) of another. It doesn't matter which is used. In this case I used <<.
and a.street_name = b.street_name
create table streetlight_arcs asThe result is that we have the arcs of many graphs (streets) described as pairs of nodes (lamp posts). All we have to do is traverse these arcs to find all the member nodes of each graph (i.e., all lamp posts in a street). Of course many of the streets will be a simple chain of arcs, but longer streets will have a (slightly) more complex topology. I suspect that the use of the geometry operator also means that all the graphs are DAGs, but I haven't attempted to verify this.
select distinct on (a.geo_id)
a.geo_id left_geo_id
, b.geo_id right_geo_id
, a.street_name
, st_distance(a.geom,b.geom) short_length
from streetlights a
, streetlights b
where 1 = 1 -- a place holder predicate to make editing easier!
and a.street_name = b.street_name
and St_Within(a.geom,St_Buffer(b.geom,75))
and a.geom << b.geom
order by a.geo_id, st_distance(a.geom,b.geom)
I've been interested in efficient ways of working with graphs in SQL databases for years. In the late 1990s I worked with a large (million+) database of customer records which had a very rich set of linkages between individual customer ids. This was for a data mining project so we needed to group the individual customer ids into something which represented the real world customer more coherently (for instance companies all controlled by the same director). As the project was a trial I had to find something which worked fairly quickly. It also had to efficient even though the data was on an MPP machine. Irritatingly I can always remember the basic principles of the alogorithm I developed, but never the nitty-gritty details.
As I wanted to do something similar with the lamp posts I've had a go at re-writing this as a Postgres Stored Procedure. What I have has none of the performance optimisation from my past implementations, but it does serve the basic purpose, of traversing a graph and producing output with each graph uniquely identified and a list of all of its member vertices. Input is a table containing arcs with each node of the arc identified by a unique integer (other columns may be present, but aren't used). Output is a table with two columns, parent_id (i.e., a unique id for the graph) and child_id (graph members). The graph identifier is merely the lowest identifier of in its set of members).
A single work table is created and one column is updated on each pass. Two queries are used per pass, one for the left vertex, the other for the right vertex. When no more rows are updated data are summarised into the output table.
CREATE OR REPLACE FUNCTION gt(
input_table character varying
, left_column character varying
, right_column character varying
, output_table character varying)
RETURNS integer AS
$BODY$
DECLARE iter integer; -- mainly used for debug purposes
DECLARE level integer;
DECLARE row_count integer := 0;
DECLARE sql_text text;
DECLARE work_table character varying := 'work_table';
BEGIN
-- Input table requires a list of arcs of a graph
-- stored as pairs of integers identifying the nodes
-- only pairs with a distance of one are required,
-- nodes must be uniquely identified by an integer
EXECUTE 'DROP TABLE IF EXISTS work_table';
-- First populate the work table with self references to all nodes
sql_text := 'CREATE TABLE work_table as
select distinct ' || left_column || ' as ' || left_column || '
,' || left_column || ' as left_uid
, ' || left_column || ' as right_uid
,' || left_column || ' as orig_min_uid
,' || left_column || ' as min_uid
, 0::integer lvl
, 0::integer iter
from
(select ' || left_column || ' from '|| input_table || '
union
select ' || right_column || ' from '|| input_table || '
) a1
union
select ' || left_column ||
', ' || left_column ||
', ' || right_column ||
', least(' || left_column || ', ' || right_column || ')
, least(' || left_column || ', ' || right_column || ')
, 1::integer lvl
, 0::integer iter
from ' || input_table || ' as a2
union
select ' || right_column || ', ' || right_column || ',
' || left_column || ', least(' || left_column || ',
' || right_column || '), least(' || left_column || ',
' || right_column || '), 1::integer lvl , 0::integer iter
from ' || input_table || ' as a3' ;
-- run the query
EXECUTE sql_text;
GET DIAGNOSTICS row_count = ROW_COUNT;
-- now do the main iteration
iter := 1;
WHILE row_count <> 0 -- exit loop when no more updates
LOOP
-- first find minimum vertex id for left vertices
sql_text :=
'UPDATE work_table
SET min_uid = a.min_uid
, iter = iter+1
FROM (
SELECT
a1.left_uid left_uid
, min(least(a1.min_uid,a2.min_uid)) min_uid
FROM work_table a1
, work_table a2
WHERE a1.right_uid = a2.left_uid
AND a1.min_uid <> a2.min_uid
GROUP BY a1.left_uid ) a
WHERE a.left_uid = work_table.left_uid
AND work_table.min_uid <> a.min_uid';
EXECUTE sql_text;
GET DIAGNOSTICS row_count = ROW_COUNT; -- then minimum vertex id for right vertices
sql_text :=
'UPDATE work_table
SET min_uid = a.min_uid
, iter = iter+1
FROM (
SELECT
a1.right_uid right_uid
, min(least(a1.min_uid,a2.min_uid)) min_uid
FROM work_table a1
, work_table a2
WHERE a1.right_uid = a2.left_uid
AND a1.min_uid <> a2.min_uid
GROUP BY a1.right_uid ) a
WHERE a.right_uid = work_table.right_uid
AND work_table.min_uid <> a.min_uid';
EXECUTE sql_text;
GET DIAGNOSTICS row_count = ROW_COUNT;
iter := iter + 1;
END LOOP;
sql_text := 'CREATE TABLE ' || output_table || ' as
SELECT DISTINCT min_uid as parent_id
, left_uid as child_id
FROM work_table ';
RAISE NOTICE '%', sql_text;
EXECUTE sql_text;
GET DIAGNOSTICS row_count = ROW_COUNT;
RETURN row_count;
END; -- gt
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100;
The algorithm works by comparing the identifiers of two or more linked nodes and always selecting the lowest which is then assigned as the parent identifier of those nodes. The process is iterated as the graph is traversed. I'm sure that at the moment it is O(n) when it should be O(log(n)), where n is the minimum length of a path across graphs. It also scans the whole table on each pass, so it needs a lot of refinement.
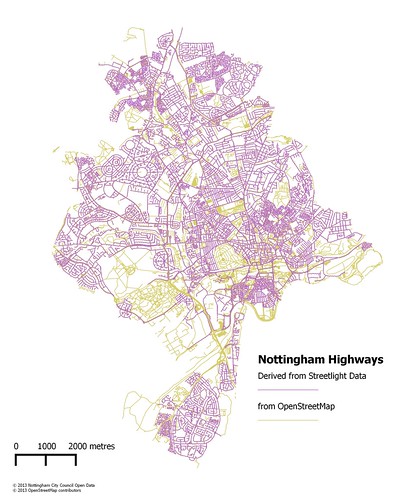 |
| Comparison of OSM highways with those derived from Streetlight data |
The first abstract image above was obtained by putting an buffered envelope around each isolated street and colour coding according to the number of lamp posts within the buffer.
The obvious use case for all this is create a navigation app for dogs (or possibly drunks). Here is a Garmin displaying an IMG file created with mkgmap just to show that this is possible!
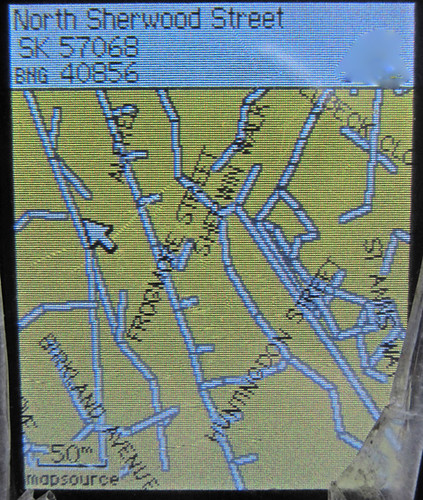 |
| Routable map on a Garmin etrex built from Street Light Open Data |
- Firstly the technique described above — of converting geodata into a graph, analysing it, and then generating additional geodata — is very useful. This is particularly so if one can convert very computationally intensive operations (PostGIS geometry functions and operators) into simple ones (integer comparisons). I have used a similar approach to assemble land polygons from the OS OpenData Meridian coastlines, which are only available as lines not areas. It is also very easy to convert various sorts of OSM data, such as highway ways, into this kind of graph within Postgres. For instance this could be used to find isolated sub graphs.
- Secondly, by enriching the data I have created some useful polygons suitable for independent verification of OSM data. This is nice because a significant proportion of street data in the UK is derived from a single source: Ordnance Survey Open Data. Whilst many names have been checked by survey, it's very nice to have another comprehensive source.
- Thirdly, it enables identification of missing residential ways: in particular named ways which are only footpaths.
- Fourthly, private roads not owned or maintained by the council are more easily picked out. I have been surprised how many new developments do not have council provided street lights (for instance Stanhope Avenue and Langdon Place). Such roads may have distinct access restrictions and other unusual features.
- Fifthly, the same sort of approach of enrichment & derivation will work with sets of data from OSM or other sources, provided that they are comprehensive.
No comments:
Post a Comment
Sorry, as Google seem unable to filter obvious spam I now have to moderate comments. Please be patient.