 |
| London Plane in Rathausgarten, Vienna Probably this one. Source: Wikimedia Commons |
- London Borough of Southwark. This was organised by Tom Chance, with a particular view to providing information on urban foraging. See his blog and a map about this.
- Vienna. The Vienna OSM community imported a file with a large number of street and park trees for the Land. (I have a minor quibble about this because they didn't cross check against already mapped trees, and I'd added a very fine Scholar's Tree in the Rathausgarten which is now duplicated).
- Bologna. A similar import which needs a bit of tidying up on the tagging.
I've played with the Vienna data before so it was a good place to see what could be done with Overpass.
.png) |
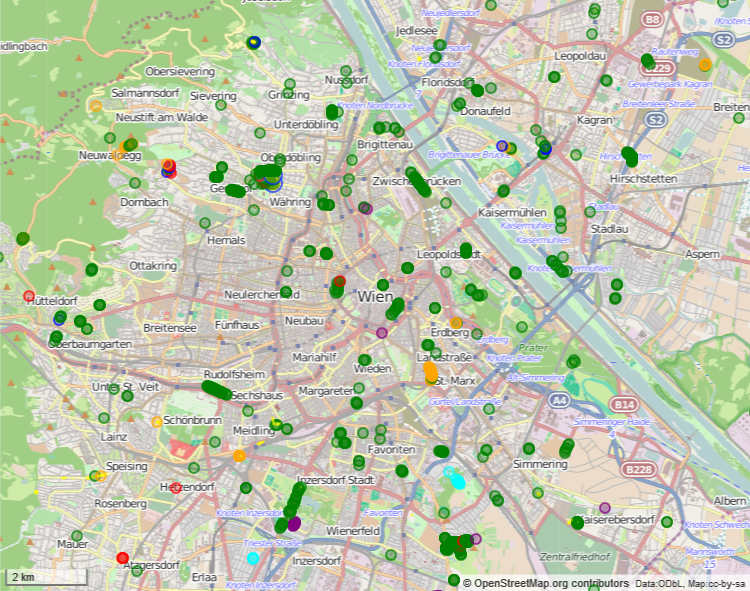
| Oak trees (Genus Quercus) in Vienna on OpenStreetMap via OverpassTurbo Species are colour coded using MapCSS as follows: green =robur; blue=petraea; red=rubra; oragnce=cerris; cyan=pubescens; purple=frainetto; small yellow dots with blue border are not identified to species. |
Oliver's interest is one of education.
@SK53onOSM @BSBIbotany nice, v useful, suppose one could create an intrsting selection, otherwise bit overwhelming as an outreach tool
— Oliver Pescott (@sacrevert) December 16, 2014
Providing a selection of interesting trees can really help people get started in learning more about the trees (and other wildlife around them). Having a large dataset, such as an entire city's tree register is far too much for this purpose. Indeed it might be too much for the person wanting to create a tree trail or even a curated list of interesting trees: it's not just location of the trees, but some will be more useful for this purpose than others. |
| Cedar of Lebanon, Wollaton Hall gardens These gardens contain several old trees of this species. Source: Andrew Abbott via Geograph |
So the question arises: "As we get more tree data in OpenStreetMap, how can we make it usable for such purposes?" In particular our focus in OSM on 'ground truth': repeatably observable features of things we map makes this more of a challenge. This is actually a general problem: as more data gets added to OSM, it can get harder to find sub-sets for particular uses.
Once again I turned to osmfilter to help resolve the problem. Firstly I created a file just containing the highly attributed trees from Vienna, using a simple filter (--keep= "natural=tree && species= && taxon= ") . An additional useful feature is that osmfilter can create simple tab separated counts of given tags, so I was quickly able to find the numbers of trees of each species: there are 265 different species comprising over 122, 000 trees. Nearly 20% are a single species, Norway Maple. Here's a pie chart of the top 20 species (about 75% of the total):
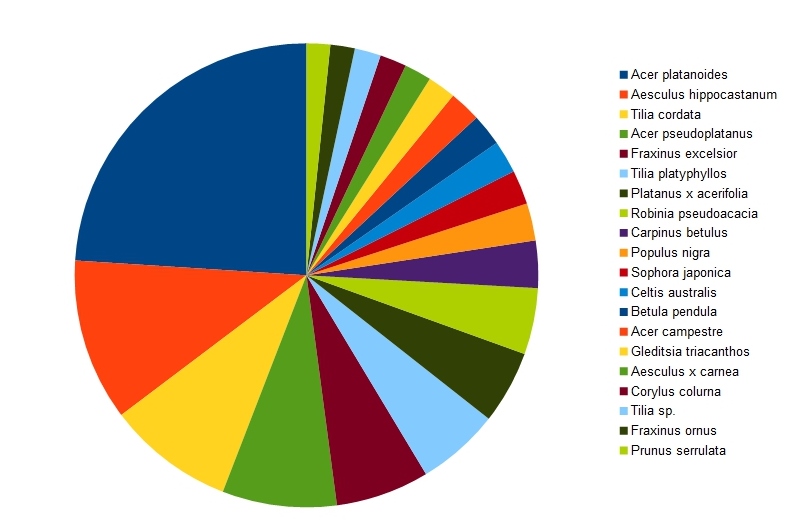 |
| The 20 commonest street trees in Vienna (total about 90,000 trees). |
Clearly with these trees we need to be highly selective in choosing examples. Indeed this might be true for any tree with over 100 specimens in the city (72 altogether). At the opposite end of the scale there are nearly 100 species with fewer than 10 specimens, and amongst these are some of considerable interest or beauty, such as Red Maple (Acer rubrum) and the Handkerchief or Dove Tree (Davidia involucrata).
 |
| Flowering Cherry Trees, Washington D.C. Examples of a collection of trees with strong seasonal interest Source: Wikimedia Commons, CC-BY-SA |
The advantage of having large data sets is that it creates the possibility of having an endless suite of walks which can start from anywhere: it's not just the centres and parks of large cities which have interesting trees.
In order to select trees for a computer-generated trail they need to be scored. We are unlikely to capture human or historical interest associated with trees on OpenStreetMap, so scoring is likely to have to rely on other factors. These are the ones I have come up with whilst writing the article:
- Native Trees. Tree walks provide a great opportunity to familiarise people with trees they might see in the countryside. As they will also have more associated wildlife they also can introduce topics such as pollination and pollinators, microfungi, plant galls etc. I would include extensively naturalised trees in this category (such as Sycamore in the UK). Scoring a tree as native/naturalised requires a list of species for a given geographical area with its status. I would be very hesitant about the sense of adding such data to OSM.
- Locally Rare or Unusual Trees. These can be determined by choosing the lowest quartile (or some other means) of all trees mapped in the district.
- Taxonomic Variety. Including trees from a good range of plant families heightens interest, but also starts building the ability to recognise characters of the family (something which I used a lot in Argentina, where much of the flora was unfamiliar). Variety within a common genus, such as different types of Oaks, or Maples is also a common theme. Taxonomic data can be acquired in an automated fashion from places such as Wikipedia or the Encylopedia of Life.
- Large Trees. Trees with a large girth are likely to be old, and distinctive. Often photogenic, but may be too large to show features of the leaves as these will be above head height. (Street trees often have lower branches and epicormic growth removed). Requires girth or diameter to be tagged.
- Avenues or other distinctive planting patterns. In principle the denotation tag allows these to be determined, but I suspect that identifying most of them will require some geospatial processing.
- Trees with non-tree tagging. In Vienna a few trees are also tagged as historic=tree_shine, and in many cities some trees are planted to commemorate events or are memorials.
- Commonest Trees. Although a tree trail's primary interest is in the less known specimens, the really common trees cannot be ignored. For instance in towns and cities throughout Europe, the London Plane is a common non-native street tree (indeed there are many in places like Buenos Aires), and many are old and large.
- Fruit Trees. Trees which produce fruits or nuts. Again would need some kind of external tabulation of properties.
- Cultivars. Other things being equal it may be more interesting to show a cultivar of a common tree, a Copper Beech rather than an ordinary one, a Norway Maple with variegated foliage rather than an ordinary one, etc.

Jacaranda in Buenos Aires
Beatrice Murch (see her blog and photos on Flickr, of Buenos Aires trees)
via Wikimedia Commons, CC-BY-SA - Beauty. An abstract & subjective property. It may be more amenable to some more objective properties, such as size of flowers, known colour of autumn foliage, listing by horticultural authorities (such as the Royal Horticultural Society).
- Seasonal Interest. If a tree's most distinctive features are only visible at certain times of year, this might be factored into altering the trial according to the season. For instance flowering cherries and other Prunus are highly valued when in flower, but not particularly rewarding at other times of year.

A reasonable balance in a trail might be a third rare trees, a third common trees, with the remaining third chosen more randomly. In other words there is an initial scoring process and then selection which uses scoring plus some mechanism to ensure variety.
We also want the trail to be more or less circular and constrained by time.
These sound like a lot of complex criteria. However, there is a nice precedent. Dimi Sztanko created walks.io a couple of years ago. This creates circular walks from a given location using a scoring system to define some measure of 'interestingness'. Needless to say I'm going to try and chat to him about the ideas above!
I've also tried out some of the ideas, by partitioning the data upto 5 classes based on ordered ranking for some of the above parameters: age, girth, height, rarity, native/non-native, cultivar or not. (I cheated and used a UK list for nativeness). Selecting all trees within about 500 metres of the Rathauspark I selected at random 4 species from the most common class, and 4 each from classes 2&3, and 4&5. This is the list I came up with:
- Acer platanoides, Norway Maple
- Betula pendula, Silver Birch
- Broussonetia papyrifera. Paper Mulberry
- Carpinus betulus
- Chamaecyparis pisifera, Sawara Cypress.
- Crataegus monogyna, Hawthorn
- Davidia involucrata, Handkerchief or Dove Tree
- Platanus orientalis, Oriental Plane
- Quercus rubra, Red Oak
- Rhamnus cathartica, Purging Buckthorn
- Sophora japonica, Scholar's Tree
- Ulmus minor
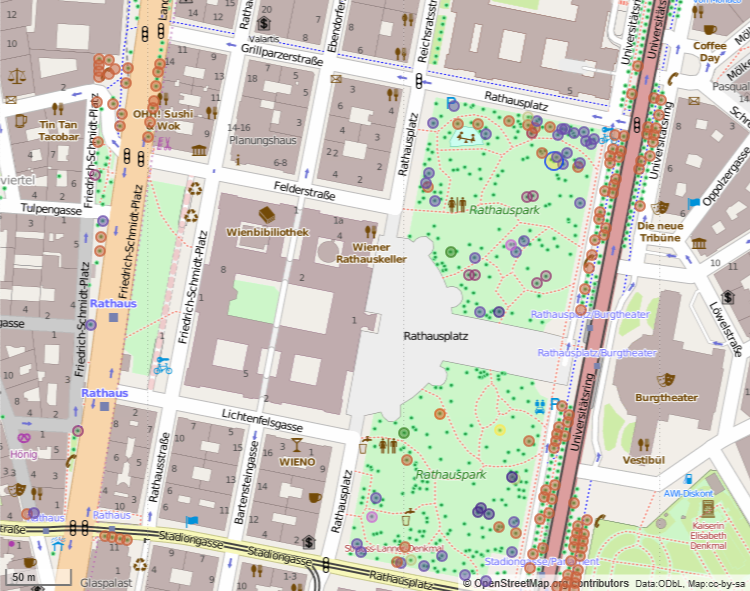 |
| Selected species around the Rathaus in Vienna Overpass Query ('cos I had trouble with QGIS) |
I used a combination of weights to select a single tree from each category.
.png) |
| The selected specimens around the Rathaus Overpass Query on Node Ids |
Now its just necessary to create a route. For this example I've done this manually.
See full screen
Of course this sort of thing is not a substitute for a trail designed by a knowledgeable person, but it does show some of the possibilities for creating thngs where such a person is not available.
I've imported trees in Brussels from the UrbIS dataset and in Kasteelpark Arenberg of KU Leuven we've been busy making an inventory with help of dendrologists. This is not an easy task. The 'Lords' of Arenberg have been importing all kinds of special varieties for their park.
ReplyDelete