Caveat: I may have missed some references to things which were highly topical in April 2011, so bear this in mind when reading the main text.
Attribution is an odd thing : the benefits are intangible, but people care a lot about it.
In the narrow sense attribution is about meeting copyright terms, but in a broader view it is about giving due credit for data, ideas or other contributions. Government bodies often insist on it. Some industries take it to extravagant lengths: compare a film from the thirties with one made now. Attribution is also at the heart of the system of citations in scholarly papers, and which blights the lives of many students, but is well nigh essential for researchers.
It's also important for OpenStreetMap (OSM). OSM is both a consumer and producer of data requiring attribution. It is also a platform for generation and testing of ideas, processes and software. In the latter case a credit or acknowledgement is the only benefit that innovators might get: one of the reasons for the naked frustration in Mikel Maron's blog post about Google's activities in Africa.
Another example showing that attribution is often the only way that the wider world gets to know that OpenStreetMap exists occurred just before Easter 2011. In a few days, many mainstream news outlets (here's a list of just a few: Guardian, WSJ Blogs, NY Times, NZZ, BBC News, LibéEcrans) showed (rather nice) OSM maps as a result of Pete Warden and Alasdair Allan's investigation of how storage of location data on iPhones and iPads (just in case you missed it link). Initially, their app didn't attribute OSM, as it was built on top of Pete's OpenHeatMap (the app I used to show toilet data). However, after a sensitively worded comment by Harry Wood, they found a bit of space, in what was no doubt a hectic round of media calls and emails, to rectify this omission handsomely.
Using Ordnance Survey Open Data I've played around with the idea of what the minimum level at which attribution is required:
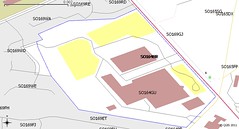
The image above shows a CodePoint Open data overlay with OS OpenData StreetView tiles underneath. The map shows the old Ordnance Survey HQ, the new one neither being in the postcode data nor on the StreetView tiles. So using these two data sources requiring attribution I used them to work out the correct postcode for this address. I could then send a letter to Vanessa Lawrence, the CEO of OSGB in an envelope like this:

Silly isn't it.
Of course I could have just looked it up on the Royal Mail Postcode Finder or the OSGB website (both of which have copyright statements), but, I didn't, I derived it from OS OpenData and those are the terms associated with the data license. So this is one problem with a catch all approach to attribution. It becomes absurd when applied to very small amounts of data (a single datum in my example). (Incidentally, the Ordnance Survey publish their attribution requirements in a PDF document which does not allow copy-and-paste: an object lesson in ensuring that licensees are less likely to follow the letter of the requirements.)
The very observant will have noticed that one of the images in this posting is not correctly attributed. I didn't notice myself until putting this together. I chose to leave it that way because it illustrates another problem. This is basically the same problem Pete Warden had.
With data mash-ups its often quicker to grab the data than to write and position the attribution statement. Several maps I've shown on this blog have used OS Boundary Line data just to make it easier to interpret the locations of a grid of points. It takes me as long or longer to get the text box for attribution as it does to query the data & create the rest of the map in QGIS. Furthermore the attribution statements are long and unwieldy compared with the importance and value of the data (for example, this pub density map).
And it's not just me getting it wrong publishing a quick screen grab. The BBC have a big "O'Reilly Media" credit on a map which is substantially OSM with an overlay: I don't see ANY attribution to OSM. So a second problem with attribution is that it's difficult to get right for a lot of modern media, particularly with rapid turn-around times. (Mind you the BBC seem to have form in this regard).
In some sense OSM is just one huge mash-up with 100,000 of data providers, many of them in turn adding data from multiple sources. Some of these data have attribution requirements associated with them, such as Ordnance Survey OpenData or French Cadastral data. Finding a reasonable way to accommodate all of this is a headache in creating a suitable balance between contributors data and the needs and realities of data consumers. I'm not going to say much more on this because this issue has exercised the OSM community for a long time, and continues to create anxiety about what is and what is not possible.
My general observation that there is a danger of privileging particular contributions, even when they are a minuscule part of the entire work. I'm aware of this because of OSM, but I believe this is real emerging issue which is far more widespread.
With more and more open data sources the opportunity to merge large numbers of different datasets becomes much easier. If I have added one street name from OSGB data for a city with several thousand should their attribution requirements over-ride other considerations? Suppose I added twenty streetnames, each from a separate source with a specific attribution requirement, how do I keep track of it let alone meet the attribution requirement?
To summarise, I think there are three main problems emerging with attribution as more open data becomes available:
- Tool chains (and data sets) don't readily support the seamless management of attribution (particularly true when outputs are not directly for a screen).
- Attribution gets in the way of the message. The attribution interferes with the actual product, just like the irritaing splash intros on DVDs. Would anyone have bought records if for every 3 minute song, there had been a 30 second audio of attribution?
- Attribution in mash-ups involving a large number of sources will be neither meaningful or proportionate. At present large probably means more than 3.
No comments:
Post a Comment
Sorry, as Google seem unable to filter obvious spam I now have to moderate comments. Please be patient.