Peter Körner (MaZderMind) has the recently made available extracts of selected areas from the OpenStreetMap full planet history. These are of various Länder of Germany, but are big enough to be interesting and small enough for repeated processing and analysis.
Handling the history of OSM edits is interesting in its own right, but it also has an immediate practical importance as some edits will not be carried forward with OSM once the OdBL licence change is completed. Tools to process and analyse the complete edit history are needed as part of this change.
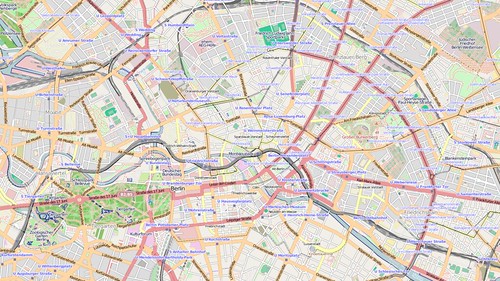
My main interest is to visualise past states of the database conveniently. The image below is of Berlin from 31st March 2009. This image was generated by re-extracting data from the history using osmosis (regular snapshot schema tables were replaced by views on history tables) and re-importing with osm2pg2sql. This process is too involved and slow for rapid visualisation of historical views of the data, but does demonstrate that reasonable results can be achieved without elaborate changes to the snapshot schema.
I'm also interested in the technical aspects of handling OSM history: I have worked on temporal database schemas in the past. Some of these were more complex than OSM, as they stored not just history of the system (transaction time), but history of the real-world (valid time). This is also something which intrigues me: how one might store real-world history in something like OSM. In OSM we don't make any attempt to discover when a pub opened or when it closed, we just know that someone added the pub to the system and that later someone removed it. Although it might seem reasonable to assume that the pub closed between the two events, it might be the original edit was by someone who used the pub 20 years ago, and it closed 19 years ago.
My initial approach is simple, some might say naive. This is to basically take a schema very similar to the current API schema and make minor modifications to it. The main change is to add another timestamp column to the main tables, with the time period between the two timestamps representing the period when the given primitive (node, way, relation) was valid. This is partly a convenience for querying the data, but it also has the advantage that we can work with partial histories if some versions are missing. The main reason for doing this, though, is to use timestamps as an additional part of the compound key for way geometries. This avoids having to generate another system key to add to the identifier and version.
Way geometries are the crucial problem in making historical data convenient to render. A given version of a way may have many geometries, depending on how many of the nodes comprising the way have changed position, and, indeed, how frequently. Each time a node changes the geometry of all its parent ways may change: of course a node might just be touched (updated with no change), or might only have its tags modified. In the first instance I ignored these issues, although about 40% of all node changes in the Berlin data do not affect position.
My first step was to find for each way version all the start timestamps for the nodes belonging to that way version and where the node version validity period overlapped that of the way version. As the way version start and end timestamps must also be considered I did this using a UNION:
SELECTIt's easy to add a valid end date column to this data using a SQL windowing function.
w.way_id,
w.version,
greatest(n.tstamp_from, w.tstamp_from) AS tstamp_from
FROM way_hist w
JOIN way_node_hist wn
ON w.way_id = wn.way_id
AND w.version = wn.version
JOIN node_hist n
ON wn.node_id = n.node_id
AND w.tstamp_from <= n.tstamp_to
AND w.tstamp_to >= n.tstamp_from
UNION
SELECT w.way_id, w.version, w.tstamp_from
FROM way_hist w
This gives us the total number of historical records we will need to store to access all distinct geometries of ways in the data set.
Exactly the same approach can be used to extend the way_nodes table with node version, and a validity date range based both on the way version and the node version. Indeed the range of way geometries can be derived from this data, but because we also need to slice up the validity range of an unchanged node for each way geometry it is convenient both conceptually and practically to keep these data separate.
With this data we can now start to generate all the historical way geometries. Unfortunately this is computationally expensive in PostGIS: one of the reasons Osmosis provides options for doing this before loading into the snapshot schema. I used the aggregate ST_MakeLine postgis function, which requires that the nodes be correctly sorted in the input.
With historic tables for nodes, ways, and way geometries created the next step was to create history tables which mimic the tables created by osm2pgsql for mapnik rendering. For nodes this is relatively simple, its just a big query converting relevant hstore data into columns along the lines of tags->'highway' as highway with the addition of my two timestamp validity columns. For ways it is more complex: the z_order and area columns requires population, and some ways need to be treated as polygons not lines. Thanks to asciiphil I was pointed to the relevant routine in the back-end processing of osm2pgsql which handles z_order. This is simple enough to replicate in SQL. For deciding which ways to add to the lines and polygon tables I used the default.style file from osm2pgsql storing this in a table.
My first pass seemed to work OK: I didn't try and turn linestrings into polygon geometries, and I didn't do anything with relations. This was the result:
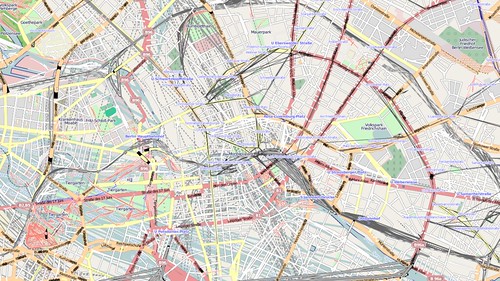
Really this is a dismal failure. Firstly running mapnik to generate the image took forever: each query was doing a table scan on the lines table rather than using the GIST index on the geometry. Secondly, it turned out that I had a problem with the generation of geometries in PostGIS: hence the lines all over the place. Node order in ways was not carried over properly into the MakeLinestring function.
Obviously, I'd hoped to get further with this, but I'm going to have to concentrate on getting the geometries right: testing using a correlated query seems to generate sensible results. That being said, small volume queries with aggregation seemed to work properly too. A kludgey solution to mapnik performance would be to just extract data in the map extent bounding box before running the mapnik style, and I may do this before looking at the PostGIS performance issues systematically.
A few other things of potential interest: the Berlin data has around 250k ways, collectively with over 600k versions. I identified around 1.6 million potential geometries for these ways. The actual number of distinct geometries is substantially smaller than this because of the high proportion of node version changes which do not affect position.
No doubt far more sophisticated things will be implemented at the upcoming hack weekend. Personally, from my experience so far, I'd like to see at least some history support in the existing tools.


