 |
| Ye Olde Trip to Jerusalem - Nottingham |
| © Copyright Richard Hoare and licensed for reuse under this Creative Commons Licence. |
I'd hoped that this would be solely concerned with the sale of alcohol as this would enable a good cross-check against mapping of pubs, bars and restaurants. However,as well as licenses for sale of alcohol on and off the premises, it includes categories for licensing of musical performances, boxing, wrestling. late-night sales and several other things.
Notwithstanding this complication, it is still an excellent basis to look at how many of the 1200 or so features are mapped on OpenStreetMap. (Note that once again I did not feel an immediate need to import the data, but firstly wanted to use it answer questions about mapping effiicacity).
All the premises come with full address data, including postcodes. I have therefore grouped the comparison results by the first part of the postcode (the postcode outer) which correspond to contiguous areas in the city. Overall over 40% have been mapped, with over 50% in the City Centre. There is no surprise that three particular outlying areas (NG3, NG5 and NG11) are poorly mapped for these types of POI: they are fairly distant from the home locations of active mappers. Many of the missing data are convenience stores and fast food outlets distributed throughout the city, which, I, for one, have not been mapping as a matter of course.
| PC Outer | Yes | No | ? No | N/A | Total |
| NG1 (Centre/CBD) | 223 50.8% |
10 2.3% |
196 44.6% |
10 2.3% |
439 |
| NG2 (Meadows/Sneinton) | 29 37.2% |
3 3.8% |
38 48.7% |
8 10.3% |
78 |
| NG3 (St Anns) | 16 20.0% |
2 2.5% |
61 76.2% |
1 1.3% |
80 |
| NG5 (Sherwood) | 25 22.3% |
2 1.8% |
83 74.1% |
2 1.8% |
112 |
| NG6 (Bulwell) | 26 31.7% |
1 1.2% |
54 65.9% |
1 1.2% |
82 |
| NG7 (Lenton/Radford) | 128 46.2% |
4 1.4% |
134 48.4% |
11 4.0% |
277 |
| >NG8 (Wollaton) | 52 40.3% |
3 2.3% |
69 53.5% |
5 3.9% |
129 |
| NG9 (Lenton Abbey) | 3 42.9% |
14.3% |
2 28.6% |
1 14.2% |
7 |
| NG11 (Clifton) | 16 29.6% |
38 4% |
54 | ||
| No Postcode | 2 28.6% |
4 57.1% |
1 14.3% |
7 | |
| Total % |
520 41.1% |
26 2.1% |
679 53.7% |
40 3.1% |
1265 |
These differences can be seen more readily when visualised with a background of Andy Allan's Transport Map. I have grouped all data by postcode and mapped this to its centroid. The very large bubble of mapped premises to the bottom left corresponds to bars in the University which all have a single postcode. These were all mapped before the end of 2008. Many missing data points are clustered along arterial roads (particularly Radford Road, Alfreton Road and Mansfield Road). Others represent parades of shops in suburban areas. The City Centre still has many features missing and is far and away the easiest place to find the missing items.
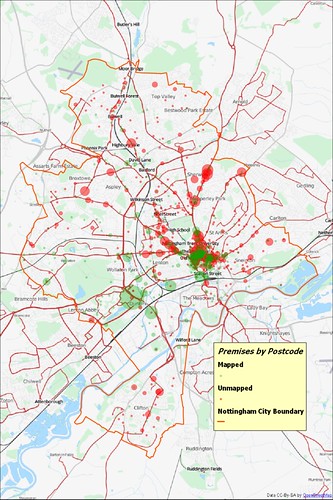 |
| Comparison of licensed premises (NCC Open Data) mapped and not mapped on OSM by postcode centroid. |
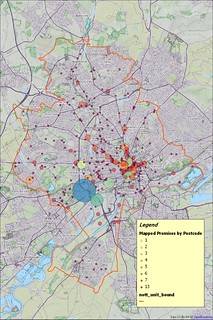
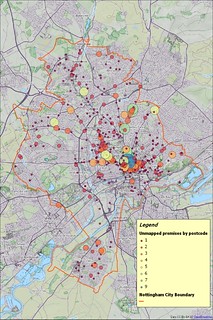
The additional maps below show mapped POIs and unmapped POIs separately. Larger versions are on Flickr.
 |
|
Some Conclusions
Here are some conclusions. They are in no particular order, and I may have missed some obvious points about this exercise.- OSM Completeness: I have no real idea if 50% completeness is good or bad. It certainly shows that there is no shortage of things to map. 50% coverage also means that OSM is still inadequate for thematic analysis (I would guess we need 80-90% coverage as a minimum). Most analyses of OSM completeness have focussed on road networks and the relative accuracy of the mapping. I'm not immediately aware of any significant studies on coverage of other types of data.
- Accuracy of Open Data: Like any data source Open Data is prone to minor errors. The most noticeable in the data under discussion are licensed premises which have either gone out of business or in extreme cases have been demolished (like the Sir John Barleycorn pub). There are also errors in names, spelling of street names, transposition of numbers in addresses, and a few cases of wrong postcodes. I have not tried to quantify these points, but would estimate it in excess of 1% of the total records. This figure is not dissimilar to our experiences with OS Open Data for street names. (There is also a big problem with addresses in that there is not a consistent address format in the data I have looked at so far).
- Automating comparisons: My comparison was done entirely manually. A more efficient means of readily comparing this type of data set is required. Comparisons can be done on similarity of names, co-location on individual streets (based on names), type of amenity (if available), and geolocation. Ideally all would be combined in some sort of overall score. Robert Scott's OSM Musical Chairs does some of these things with a specific set of open data, OS Locator. We could do with more general tools to attack the broader problem, and to provide convenient ways for driving survey activity (see below).
 |
| Shops surveyed in Sep. 2009, mapped Mar. 2013 |
- Enabling use of old surveys: Although, I do not, in general, map fast food outlets, I have quite frequently noted them during surveys: either using photos or on audio. I have always been very reluctant to use this data long after the survey, and thus most have never been transferred to OSM. An independent source, such as the licensed premises file, means that a cross-check is available to show whether these outlets are still present. Thus the most immediate useful mapping I have been able to do is to look through old survey data, some dating back to 2009, as shown in the image, and add missing features to OSM.
- Enriching existing data: as the data contains both postcode and address, it has been possible to add the house number and postcode to many pre-existing nodes and ways. These in turn allow further enhancement of addresses in the near neighbourhood of any feature. We may learn which side of a road has odd or even addresses, or be better able to predict the bounds of a postcode. I will return to this in a later post because there are other similar datasets which can be used for the same purpose.
- Driving OSM Mapping activity: a partially geo-located file (and these are only partial because only the postcode centroid location is known), can make it much easier to target the mapping of the missing data. For instance, we know that some 9 POIs are still missing in the large entertainment block called The Cornerhouse. Similarly, photo mapping on a couple of inner-city roads should pay dividends. Also minor name changes can be picked up from the file. In this way I was able to update the Bombay Delight restaurant.(Postscript: after I'd written most of this post I went out to the pub on Friday night: I took the opportunity to collect around 25 of these missing POIs in just under 30 minutes, thus pushing NG1 close to a 60% match to the open data source).
Robert very kindly modified his 'musical chairs' code to provide a similar tool for an open data set covering allotments in London:
ReplyDeletehttp://ris.dev.openstreetmap.org/dsmusicalallotments/map
http://wiki.openstreetmap.org/wiki/London/Datastore_allotments
This version allows allows one to annotate entries, for example you will see that I surveyed every entry in Southwark where there was a disagreement with OSM and noted the reasons behind the six disagreements.
I don't know how much of a hack that was, and whether it would be possible to modify it to take any number of different datasets.