 |
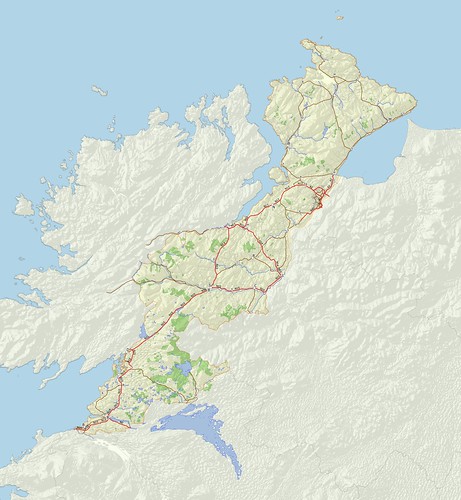
| H34 West Donegal: Vice County raster map suitable for MapMate Source data: (c) OpenStreetMap contributors; hill shading NASA SRTM via viewfinderpanoramas.com |
One of the things I'd always planned to do once I had a half decent data set for the Irish Vice Counties was to create detailed raster maps for each of them. This is mainly because I've found using such raster maps useful for my own biological recording using MapMate software. They make choosing the correct recording location much easier, and reduce the hassle in producing more attractive (and communicative) outputs. I've detailed the principles behind the creation of such maps here in the past.
With the first such map I produced I struggled to get it to align properly with the Irish Grid displayed with MapMate. I could upload MapInfo .MIF files which would align, but these offered nothing like the degree of detail I want to show. Furthermore the import process with my copy of MapMate only seems to work with polygons. I tried a variety of ways: mainly trying to tweak the .TAB file format which I'd used successfully with files for Great Britain.So I put the idea to one side.
Very recently, prompted by Julia Nunn, VC recorder for County Down, I re-looked at the problem. Once again I was getting nowhere and I was on the verge of seeking expert help from Richard Cantwell on the arcana of MapInfo's formats, many of which date back to the 1980s. (Richard works professionally with MapInfo data a lot and has written some very informative articles available from his firm's website.)
Note. Much of this post will mainly be of interest to users of MapMate. However, towards the end I digress into geonerd territory when discussing the pros and cons of MapMate's technical choices about projections. Also please note that has been sitting in my draft folder for a while before being published.